La question maintenant est de savoir si les NGs et les SGs peuvent être considerés comme deux échantillons dérivés de la même distribution, ou si la distribution réelle ou les paramètres de l'algorithme utilisé pour les identifier sont à l'origine de cette différence.
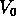 pour sélectionner les groupes
(350 km/s pour les NGs contre 600 km/s
pour les SGs). Un paramètre
pour sélectionner les groupes
(350 km/s pour les NGs contre 600 km/s
pour les SGs). Un paramètre 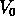 trop grand serait la cause
d'une plus grande proportion de galaxies apparement dans un groupe
qui en réalité n'en sont pas membres ( interlopers).
Je ne crois pas que ce soit l'explication
correcte, car cet effet n'est pas très grand par rapport
au contraste de densité.
trop grand serait la cause
d'une plus grande proportion de galaxies apparement dans un groupe
qui en réalité n'en sont pas membres ( interlopers).
Je ne crois pas que ce soit l'explication
correcte, car cet effet n'est pas très grand par rapport
au contraste de densité.
Pour vérifier cette explication,
j'ai donc calculé 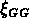 pour deux sous-échantillons de NG2,
l'un avec les 72 groupes qui ont un nombre de membres
pour deux sous-échantillons de NG2,
l'un avec les 72 groupes qui ont un nombre de membres
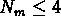 , l'autre avec les 56 groupes
qui ont
, l'autre avec les 56 groupes
qui ont 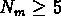 .
Les résultats, qui sont très bruités, montrent
que les groupes riches ont une longueur de corrélation
plus grande (6.6 contre 4.4) que les groupes pauvres.
La fraction supérieure de groupes pauvres semble
aplatir la pente de
.
Les résultats, qui sont très bruités, montrent
que les groupes riches ont une longueur de corrélation
plus grande (6.6 contre 4.4) que les groupes pauvres.
La fraction supérieure de groupes pauvres semble
aplatir la pente de 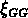 et en réduire l'amplitude.
Entre 6 et 7
et en réduire l'amplitude.
Entre 6 et 7 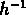 Mpc la fonction de corrélation
Mpc la fonction de corrélation 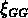 de
tous les sous-échantillons NG montre un maximum secondaire,
tandis que entre 7 et 8
de
tous les sous-échantillons NG montre un maximum secondaire,
tandis que entre 7 et 8 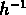 Mpc la
Mpc la 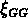 de tous les sous-échantillons
SG montre un minimum secondaire, ce qui rend plus plate
la
de tous les sous-échantillons
SG montre un minimum secondaire, ce qui rend plus plate
la 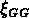 nord et plus raide la
nord et plus raide la 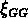 sud.
sud.
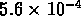 et
et
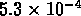 , tandis que les échantillons SG1 et SG2 ont
des densités respectivement de
, tandis que les échantillons SG1 et SG2 ont
des densités respectivement de
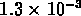 et
et 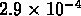 , approximativement
deux fois plus grandes.
Des différences significatives dans l'estimation de la fonction de
corrélation peuvent être generées
suivant si l'on utilise, comme densité de normalisation,
le nombre d'objets divisé par le volume total
de l'échantillon, comme dans le cas des groupes, ou si l'on calcule
l'intégrale de la fonction de luminosité
(Blanchard et Alimi, 1988). En effet
il est impossible de déterminer une vraie densité moyenne des groupes
dans les petits échantillons actuellement disponibles.
Pourtant cet effet devrait diminuer l'amplitude de la
, approximativement
deux fois plus grandes.
Des différences significatives dans l'estimation de la fonction de
corrélation peuvent être generées
suivant si l'on utilise, comme densité de normalisation,
le nombre d'objets divisé par le volume total
de l'échantillon, comme dans le cas des groupes, ou si l'on calcule
l'intégrale de la fonction de luminosité
(Blanchard et Alimi, 1988). En effet
il est impossible de déterminer une vraie densité moyenne des groupes
dans les petits échantillons actuellement disponibles.
Pourtant cet effet devrait diminuer l'amplitude de la 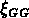 des
groupes CfA, et ne peut donc pas expliquer la différence observée.
des
groupes CfA, et ne peut donc pas expliquer la différence observée.
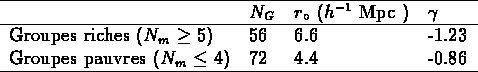
Table: Paramètres de la fonction de corrélation des groupes CfA
``riches" et ``pauvres"