Acidi nucleici: DNA e RNA
Grazie alle scoperte di J. D. Watson, F. H. C. Crick ed M. H. F. Wilkins, premi Nobel per la medicina nel 1962, oggi noi sappiamo che l'immensa quantità di informazioni necessarie alla "costruzione" degli esseri viventi è iscritta, a livello molecolare, in un lungo filamento doppio, formato da vari composti chimici noto come DNA o acido desossiribonucleico. Tutta la particolarità di questa molecola risiede nella sua capacità di autoduplicarsi o di fornire delle copie di suoi tratti particolari. Analizziamone la struttura di base utilizzando un modellino per comprendere l'importanza di questo meccanismo (Fig. 1).
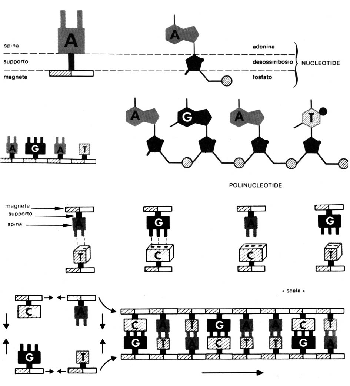
Figura 1. Schema strutturale del DNA.
Consideriamo delle spine e delle prese doppie e triple. Immaginiamo che queste prese o spine siano dotate di una base magnetica caratterizzata da due poli in grado di esercitare una debole attrazione nei riguardi delle basi contigue. Mettendo alla giusta distanza molti di questi elementi è possibile ottenere un filamento di prese e spine affiancate. Volendo creare un secondo filamento complementare al primo, la nostra libertà di azione sarà limitata dal fatto che, in corrispondenza della presa doppia del primo filamento, potremo usare, nel secondo filamento, solo la spina doppia e non la tripla. Quest'ultima potrà essere usata solo in corrispondenza della spina tripla. E viceversa. In pratica in questo modo è possibile ottenere una specie di scala in cui i supporti magnetici formeranno i montanti laterali, mentre i pioli saranno rappresentati dalle prese e dalle spine complementari. Se chiamiamo G la spina tripla, C la presa tripla, A la spina doppia e T la presa doppia, gli unici accoppiamenti possibili saranno tra la G di un filamento e la C dell'altro (o viceversa) e tra la T di un filamento e la A dell'altro (o viceversa). Nessun limite è posto alla lunghezza del filamento. In questo modo è possibile ottenere, ad esempio, un filamento formato da G-T-A-C-T-T che avrà come filamento complementare C-A-T-G-A-A. Si vede subito che la sequenza delle singole lettere può servire da base per un codice, esattamente come una serie di punti e linee rappresenta la base del codice Morse.
Il DNA è strutturato secondo un modello analogo. Il composto è infatti formato da due lunghissimi filamenti ottenuti dall'unione di quattro elementi detti basi: la Guanina, la Citosina, la Timina e l'Adenina. Queste sono ancorate ad un supporto chimico rappresentato da un zucchero, il deossiribosio, e ad un composto chimico ricco di energia (un fosfato). Il fosfato, grazie alla sua energia, collega tra di loro le molecole di zucchero in modo da formare i montanti della scala. Le basi, invece, si susseguono nei due filamenti a formare i pioli della scala disponendosi in modo tale che la Guanina abbia sempre di fronte la Citosina e che la Timina abbia di fronte, sul filamento complementare, l'Adenina. Le basi sono unite da un debole legame chimico. I due filamenti così formati sono avvolti tra di loro a formare una doppia elica spirale (Fig. 2). In pratica, per visualizzare una molecola di DNA, basta immaginare una scala che, presa per le due estremità, venga ritorta nei due sensi. Lo zucchero, il fosfato ed una base, uniti tra di loro costituiscono un nucleotide. I filamenti di DNA sono quindi formati da una successione di nucleotidi. La successione delle basi lungo il filamento identifica un codice genetico di 4 lettere, G, C, T, A. La lettura di questo codice avviene per gruppi di tre lettere. Ad esempio, volendo leggere la successioni delle basi lungo il filamento T-A-G-C-A-A, dovremmo considerare che, a partire dal punto inizio lettura, T-A-G rappresenta un'informazione e C-A-A un'altra informazione. Questi gruppi di tre lettere vengono detti triplette. Considerando la lunghezza dei filamenti di DNA, è facile immaginare le migliaia di triplette che in esso si susseguono e, conseguentemente, le migliaia di informazioni. L'insieme delle informazioni contenute in un particolare tratto di DNA identifica un gene. I geni contengono le informazioni relative a tutti i caratteri propri di quel determinato organismo (genotipo). Ma in che modo l'informazione contenuta nei geni si manifesta, a livello strutturale e funzionale, nell'organismo vivente? Qual è il meccanismo che consente di mantenere pressoché inalterata questa informazione, generazione dopo generazione?
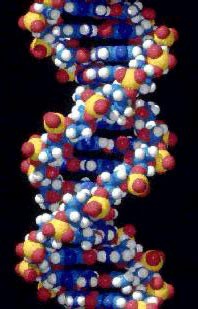
Figura 2. Rappresentazione grafica del DNA.
Immaginiamo di aprire i due filamenti di DNA in modo da poterli successivamente completare con altri nucleotidi liberi presenti nel nucleo. Questi andranno ad appaiarsi ai singoli filamenti aperti secondo la regola delle basi: Citosina con Guanina (e viceversa), Adenina con Timina (e viceversa). È evidente che rispettando l'appaiamento tra basi complementari, dal filamento originale di DNA se ne possono ottenere 2 uguali, in quanto i singoli filamenti originali fungono da matrice per la costruzione di filamenti complementari.
Grazie a questa capacità di autoreplicarsi, il DNA è in grado di produrre copie di se stesso o copie di suoi tratti a seconda se sia necessario duplicare integralmente l'informazione in esso contenuta o fornire un informazione parziale, quella, ad esempio, utile a consentire la sintesi di una determinata proteina.
Oltre al DNA, nella cellula è presente un altro tipo di acido nucleico: l'RNA o acido ribonucleico. Esistono diversi tipi di RNA, per i nostri scopi è tuttavia sufficiente analizzarne solo due: l'RNA messaggero (mRNA) e l'RNA di trasferimento (tRNA). A differenza del DNA, l'RNA è un acido nucleico a filamento singolo; è costituito da una catena di nucleotidi analoga a quella del DNA ma una delle basi, la Timina, è sostituita da una base differente: l'Uracile. Gli RNA svolgono un ruolo importantissimo nella traduzione del messaggio contenuto nel DNA e nella conseguente sintesi delle proteine.